Introduction
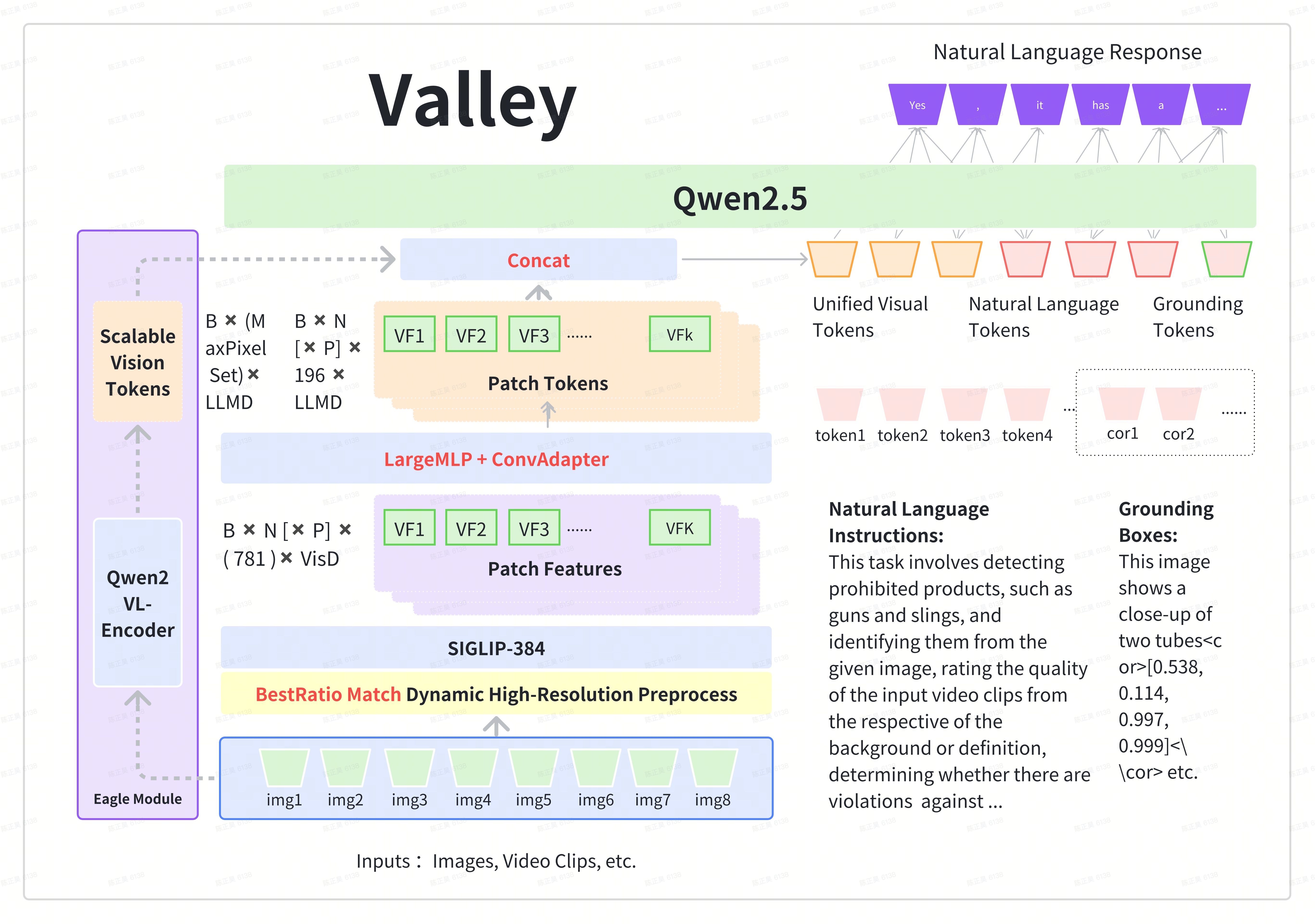
Valley is a cutting-edge multimodal large model (MLLM) designed to handle a variety of tasks involving text, images, and video data, which is developed by ByteDance.
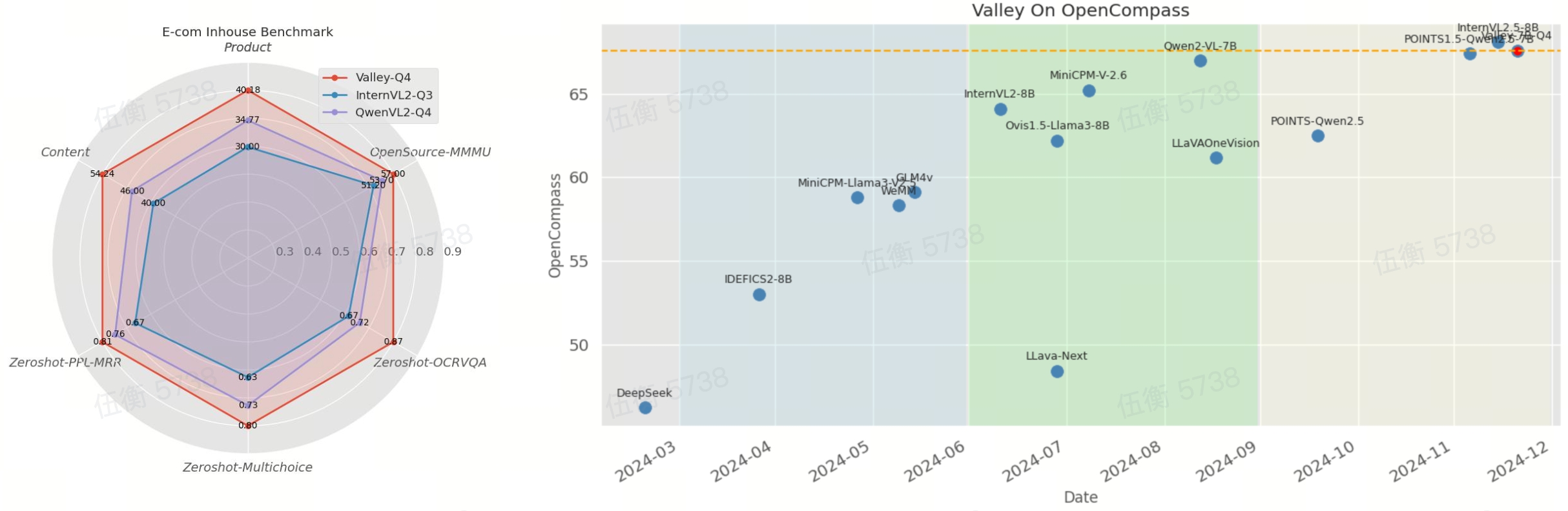
Our model achieved the best results in the inhouse e-commerce and short-video benchmarks, much better then other SOTA opensource models.
And it has also demonstrated comparatively outstanding performance on OpenCompass, a renowned multimodal model evaluation leaderboard.
With a average score of 67.40, it ranks top2 among the known open-source MLLMs (<10B).
Performance
| Models | Average | MMBench | MMStar | MMMU | MathVista | Hallusion Bench |
AI2D | OCRBench | MMVet | |
|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary models | ||||||||||
| SenseNova | 77.4 | 85.7 | 72.7 | 69.6 | 78.4 | 57.4 | 87.8 | 894 | 78.2 | |
| GPT-4o-20241120 | 72.02 | 84.3 | 65.1 | 70.7 | 59.9 | 56.2 | 84.9 | 806 | 74.5 | |
| Gemini-1.5-Pro-002 | 72.14 | 82.8 | 67.1 | 68.6 | 67.8 | 55.9 | 83.3 | 770 | 74.6 | |
| Open-source models | ||||||||||
| InternVL2.5-8B | 68.11 | 82.5 | 63.2 | 56.2 | 64.5 | 49 | 84.6 | 821 | 62.8 | |
| POINTS1.5-Qwen2.5-7B | 67.35 | 80.7 | 61.1 | 53.8 | 66.4 | 50 | 81.4 | 832 | 62.2 | |
| BlueLM-V-3B | 66.11 | 82.7 | 62.3 | 45.1 | 60.8 | 48 | 85.3 | 829 | 61.8 | |
| MiniCPM-V-2.6 | 65.16 | 78 | 57.5 | 49.8 | 60.6 | 48.1 | 82.1 | 852 | 60 | |
| Ovis1.5-Llama3-8B | 62.25 | 76.6 | 57.3 | 48.3 | 63 | 45 | 82.5 | 744 | 50.9 | |
| LLaVA-OneVision-7B (SI) | 61.18 | 76.8 | 56.7 | 46.8 | 58.5 | 47.5 | 82.8 | 697 | 50.6 | |
| Ours | ||||||||||
| Valley-7B | 67.40 | 80.68 | 60.93 | 57.00 | 64.6 | 48.03 | 82.48 | 842 | 61.28 | |
Overview
BibTeX
Comming soon ...